Final Devoicing in the German of Native English Speakers
by Holly Griffis

Final devoicing in linguistics refers to the devoicing of syllable-final voiced consonants. Voiced consonants require the vocal cords to vibrate, whereas devoiced consonants are made without vocal cord vibration. Final devoicing is a characteristic of the German language, but English does not utilize it. Because of this fact, many native English speakers may not utilize final devoicing in their German, or they may utilize it to a lesser extent than what is expected for German. In this study, voice onset time was used to determine whether final devoicing was occurring or not. For native English speaker 1, each voiced plosive had a VOT between 25-35 milliseconds, and for native English speaker 2, all but one of the voiced plosives had a VOT between 25-30 milliseconds. This paper demonstrates that a native English speaker will likely be either English-like in their pronunciation of syllable-final voiced con-sonants when speaking German or something in between English-like and German-like due to seeping (Grosjean 2008), the influence of their first language on their second.
Seeping occurs when an individual’s dominant language influences any non-dominant language they speak. This influence can range from the grammar to the lexicon to the phonetic aspect of the spoken language. This theory explains why an individual might exhibit structures that are present in their native, dominant language in a different language where those structures do not exist.
In this study, German final devoicing was examined for evidence of seeping since it does not occur in English. Final devoicing occurs when voiced plosives become devoiced in the syllable-final position. The plosives [d], [g], and [b] will be devoiced and phonetically become /t/, /k/, and /p/, respectively. Thus any voiced plosive in the syllable-final position will be phonetically indistinguishable from their voiceless counterpart in these minimal pairs (“Rad” would sound the same as “Rat”).
Final devoicing can be determined by examining the VOT(final) for the plosives in the syllable-final position. VOT, voice onset time, is the time from the release of a plosive to the beginning of vocal fold vibration. For a voiced plosive the VOT(final) is expected to be in the range of 0-20 milliseconds, whereas voiceless plosives are expected to be in the range of 50-80 milliseconds. The longer VOT for a voiceless plosive is due to the release of air that occurs between the initial sound of the consonant and the next vowel or consonant sound. If final devoicing occurs, we would expect any voiced plosives to devoice and have a VOT(final) between 50-80 milliseconds. If the range for these voiced plosives is between 0-20 milliseconds, then devoicing is not occurring. If it is between 20-50 milliseconds, then the speech is neither patterning German (50-80 milliseconds) nor English (0-20 milliseconds), but something in between. If devoicing is not fully realized in the German of a native English speaker, this would suggest that their English seeps into their German.
Method
For this study, individuals were given a list of words to read aloud in place of the blank in the following sentence: “Kannst du _____ für mich sagen?” (‘Can you say _____ for me?’) The list of words consisted of a mix of relevant words that could be analyzed for final devoicing and distractor words. Subjects were recorded speaking the words, and the recordings were analyzed using the software Praat, which allows for the length of consonants to be measured. Each relevant word was then examined and the VOT(final)s for the syllable-final consonants were measured. The participants in this study included two native English speakers who have German as their L2 and a native German speaker as a control.
The words were analyzed in minimal pairs to better examine the level of devoicing that occurred. The three pairs analyzed were Rad/Rat (wheel/advice), Bad/Bat (bath/asked), and Bang/Bank (scared/bench). The VOT was measured for the [d], [t], [g], and [k].
Data and Analysis
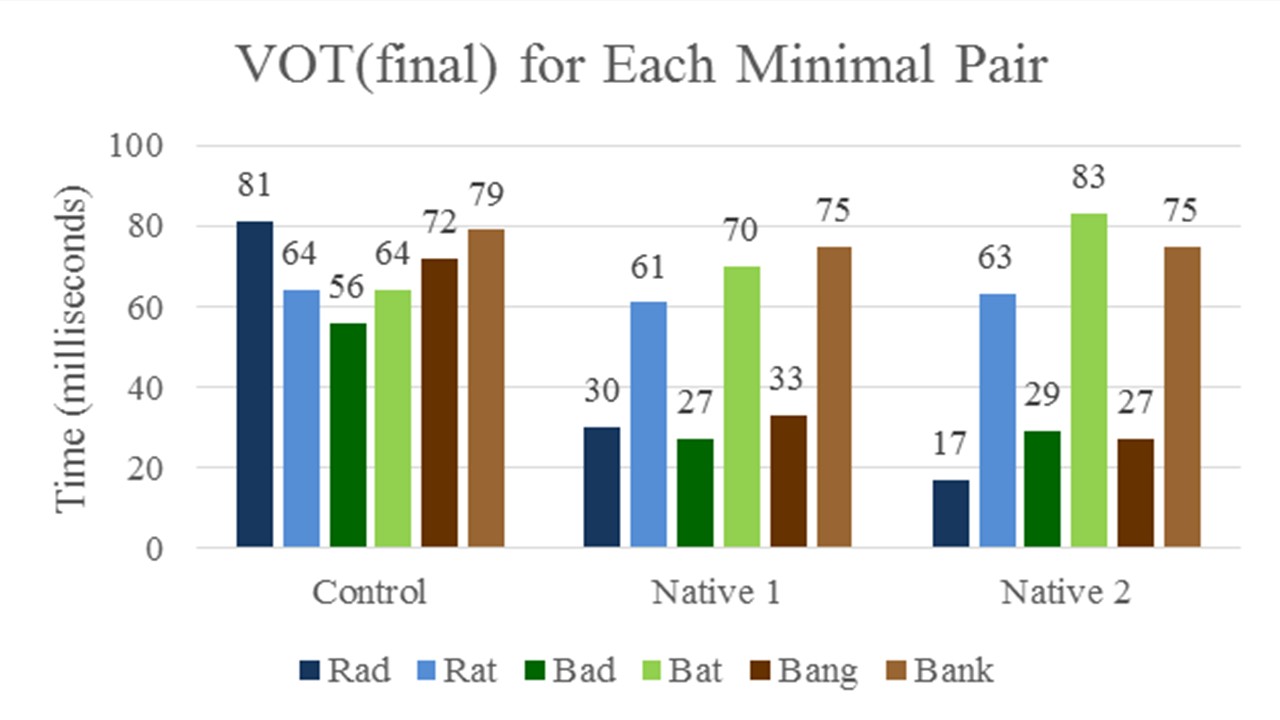
Figure 1. VOT(final) measurements for each minimal pair for each participant.
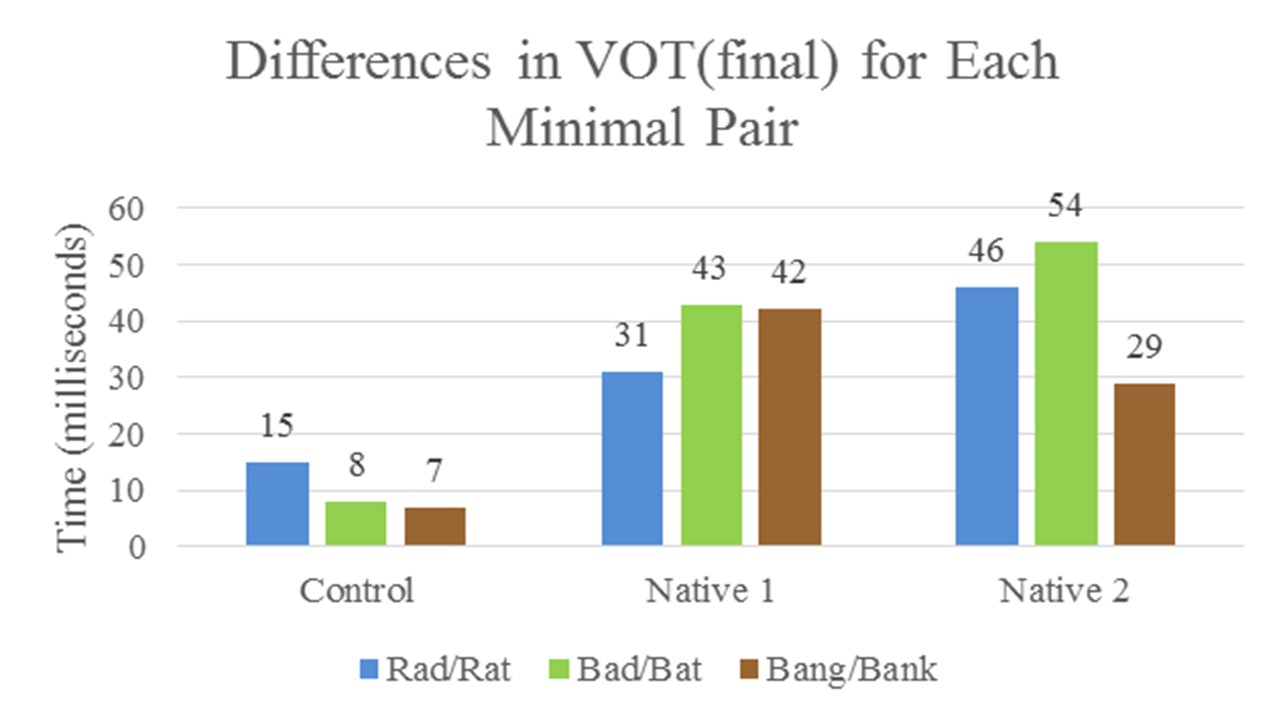
Figure 2. Differences between each word in each minimal pair for each participant.
For each minimal pair, the control utilized final devoicing, meaning that each plosive was in the German-like 50-80 range for the voiced plosives (Figure 1). Within each minimal pair there was no more than a 15 millisecond difference (Figure 2). A difference of 20 milliseconds or more is required for a difference to be perceived, meaning that each word in these minimal pairs are indistinguishable from each other and context would be required in order to understand which word is being spoken, as would be expected for a native German speaker.
For native English speaker 1, each voiced plosive was between 25-35 milliseconds (Figure 1), meaning that each voiced plosive was neither in the English-like 0-20 range nor in the German-like 50-80 millisecond range. All of the differences within the minimal pairs for this speaker were between 31 and 43 milliseconds (Figure 2). For native English speaker 2, the [d] in the word “Rad” was 17 milliseconds, meaning that it was voiced in the English-like range, but all other voiced plosives were between 25-30 milliseconds and were neither in the English-like range nor the German-like range. All of the differences within the minimal pairs for this speaker were between 46 and 54 milliseconds (Figure 2). For both of the native English speakers, all of the differences within the minimal pairs were longer than 20 milliseconds (Figure 2), meaning these differences in the minimal pairs are perceivable.
With each speaker, all of the unvoiced plosives were in the 50-80 millisecond range, which is expected for both English and German. The first native English speaker had been learning German for 9 years. The second native English speaker had been learning German for 7 years, had spent time studying abroad in Germany, and had been a part of an exchange program in Germany.
Discussion
Since the native English speakers have English as their dominant language, it is possible that English influences various aspects of their German. With regards to final devoicing, neither of the native English speakers utilized final devoicing to the extent that the native German control did. What would be expected in English is for each voiced plosive to be in the 0-20 millisecond range, but in German it would be expected to be in the 50-80 millisecond range. Since neither of the native English speakers fully devoiced the voiced plosives, and the second native English speaker pronounced one voiced plosive in the English range, it is possible that this is caused by seeping of their dominant language (English) on their German. If seeping is occurring, this suggests that individual languages are not isolated from each other in the mind when language is being produced. Any part of one language can be woven into another language if its influence is strong enough. The speaker may be learning German and attempting to devoice voiced plosives in the syllable-final position, but the influence of English is so strong that devoicing does not fully occur. As a native English speaker practices German and has more linguistic domains for German, one would expect the influence of English to decrease, and the speaker would be expected to utilize more final devoicing in their German.
This study provides some insight as to what may be occurring in the mind when language is produced and adds to the pre-existing evidence of seeping. It can be expanded on by using more participants with varying backgrounds with learning German and varying numbers of linguistic domains in order to build more evidence to support seeping and to assess any influence on final devoicing due to linguistic domains. This study can also be expanded on by examining more minimal pairs or by changing the method from reading a list of words inserted into a question to reading texts that contain the minimal pairs.
Works Cited
Grosjean, François. 2008. Studying bilinguals. Oxford: Oxford University Press.
Holly Griffis is a graduate of the University of Georgia where she studied the German language, psychology, and biology. The focus of her studies has been on human sexuality and gender studies. In her spare time she contributes to the LGBT community, fosters animals, tutors in math and science, and practices singing and playing percussive instruments. She intends on attending medical school and becoming a psychiatrist so that she can work with and counsel those in need in the transgender community.
Citation style: APA