Indonesian versus English Revisited
More Similarities Unveiled
by Drew Felt

Following up on Wolfman’s Parallelism in Language: A Cross-Linguistic Analysis of English and Indonesian (this issue), this paper aims to consider similarities between the two unrelated languages in order to discuss the underlying, universal nature of human language as a whole. With specific regard to the syntactic structures of these languages, this paper considers commonalities in the word ordering procedures that contribute to the infinite, generative potential that each language possesses. An important topic in this paper is the question of headedness, or the position in which the main syntactic unit of a phrase (the head) may be found, and how, despite a large degree of variation in the ways in which languages approach this, many common features persist in completely unrelated languages, like English and Indonesian. This paper posits that those common features are the results of underlying, deep-structural tendencies that are inherent in human language, ultimately considering the hypothetical Universal Grammar that all humans may possess.
Keywords: Syntax, Universal Grammar, Subject, Predicate, Headedness
Upon hearing Indonesian, Turkish, Japanese, or German for the first time, any native speaker of English could instantly point out many differences from their mother tongue. Most apparent of these differences would be phonetic and phonological observations, only beginning to scratch the surface of what the various linguistics subfields explore. While these more apparent differences are, of course, important for linguistics as a whole, on a deeper level, the many features these languages have in common demand equal if not greater attention. One of the formal and thus perhaps less widely accessible subfields of linguistics is syntax, which aims to understand the rules of language that govern word order, all combining to form what is called a grammar. A pillar of linguistic study, syntax describes the ways a language’s grammar may take form so that we, as syntacticians, may understand both the many ways in which language may vary and the underlying commonalities found within all human language. This paper will compare the basic syntax of English and Indonesian to highlight these differences and similarities as a means of explaining how both may potentially be found within any pair of natural languages.
To start this discussion, I will review basic syntactic concepts by making a grammar for English. To construct a language’s grammar, syntacticians first have to describe its lexicon, which is essentially the ‘dictionary’ that exists within the minds of native speakers. In doing this, the main goal of the syntactician is to understand what part of speech each word is categorized as. An example of a small lexicon in English could look like the following table, for instance:
Sample English Lexicon:
| Noun | dog(s), steak(s), house(s), pan(s) |
| Verb | eat(s), cook(s), talk(s), turn(s) |
| Adjective | brown, happy, French |
| Determiner | the, a, our |
| Preposition | on, in, about, with |
| Intensifier | really, quite |
Once these categories are assigned, we can try creating sentences to see what potential word orders are grammatical within the language.
- The dogs cook.
- Our dog eats.
- Our happy dogs eat a really brown steak in the French house.
- *Our dogs happy eat steak brown in the house French.
- A dog talks about the brown ball.
- *Talks about the brown ball a dog.
Looking at these examples, it is abundantly clear to any speaker of English which sentences are grammatical and which ones are ungrammatical. In the two ungrammatical examples (marked with an asterisk (*)), the ungrammaticality stems from an incorrect word order. Looking at examples (3) and (5), which offer the same lexical insights as (4) and (6) but are grammatical, we can see a clear representation of the correct word order for these parts of speech in English.
We can break the grammatical examples down in a hierarchical order to understand how these constructions work. First, we can start at the sentence level. In English, a sentence (S) must contain a subject noun phrase (NP) and a predicate verb phrase (VP). Since this is the case without exception, and examples (5) and (6) show us that the subject must precede the predicate, we can write a phrase structure (PS) rule for English sentences:
S → NP VP
This is the most common style for denoting phrase structure, and it should be read as:
A sentence (S) consists of (→) a noun phrase (NP) and then a verb phrase (VP).
With this rule, we should be able to plug any NP into the subject slot and any VP into the predicate slot to form a grammatical sentence. Now, we can elaborate on what constitutes an NP and a VP.
First, consider the following example NPs:
- steak
- *the
- our quite French ball
- *quite French our ball
- *our ball quite French
- steak in the house
- *in the house steak
Looking at these examples, there are a number of generalizations we can make about English NPs. Looking at example (1), we can see first that an NP can be grammatical as just a noun, but, as we can see in example (2), this is not the case when there is just a determiner. Because of this, we know that the determiner is optional, but the noun is obligatory. Likewise, we can see that an adjective phrase (AP) is also optional since there is not one present in example (1). Examples (3)–(5) show us that the correct order of all constituents together is determiner, AP, noun since putting them in any other order is ungrammatical. Finally, since example (7) is ungrammatical, we know that a prepositional phrase (PP) should follow the noun. Since none of the other examples use PPs, we can ascertain that these phrases are also optional. Now, we can write a PS rule for English NPs:
NP → (D) (AP) N (PP)
Determiners, APs, and PPs are put in parentheses to connote that they are not obligatory.
Before we return to the predicate, we should define the two new phrases that we have added to our NP rule: the AP and the PP. Consider the following AP examples:
- quite brown
- *red quite
- red
- *quite
Using this data, we can see that an AP can be made up of an intensifier (INT) and an adjective (A). Based on examples (1) and (2), we can determine that the INT should precede the A it modifies. Also, we can determine that the A is obligatory since it stands alone in example (3) without an INT, but the reverse is not grammatical as we can see in example (4). Ultimately, we can write our rule for an English AP:
AP → (INT) A
Next, the following examples provide data related to PPs:
- in the house
- *the house in
- *in
- *the house
We can see in example (1) that an English PP is made up of a preposition (P) plus an NP. When comparing examples (1) and (2), we can see that the P must precede the NP. Finally, since examples (3) and (4) both lack one of these constituents and can no longer be considered complete PPs, we affirm that they are both necessary components of the phrase. Thus, we can write our PP rule as follows:
PP → P NP
Now that all parts of our subject NP have been defined, we can do the same for our predicate. Consider the following VPs:
- cooks
- ate the steak
- talks about the house
- turns brown
- turns the steak brown in the house
- *turns brown the steak in the house
- *turns in the house the steak brown
Based on examples (2)–(4), an English VP can feasibly allow for an NP, AP, or PP but does not require any, as we can see in example (1). Accordingly, all non-verbal elements of this phrase are optional. As examples (5)–(7) demonstrate, the NP must be the first constituent to follow the verb, then the AP, then the PP; any other ordering would be ungrammatical. In light of these observations, the following VP rule stands:
VP → V (NP) (AP) (PP)
Now, we have a strong framework for English PSs:
S → NP VP
NP → (D) (AP) N (PP)
VP → V (NP) (AP) (PP)
AP → (INT) A
PP → P NP
With these rules, we should be able to make grammatical sentences that can be diagrammed on syntax trees. This specific type of tree-diagram is an important tool for syntacticians since it can be used to show the underlying PSs within a sentence by starting at the most broad level (i.e., the sentence) and branching outward with each new phrase. This is helpful because it elegantly shows which syntactic units are present and how each unit is hierarchically related to everything else in the sentence. An example of such a tree is modelled below:
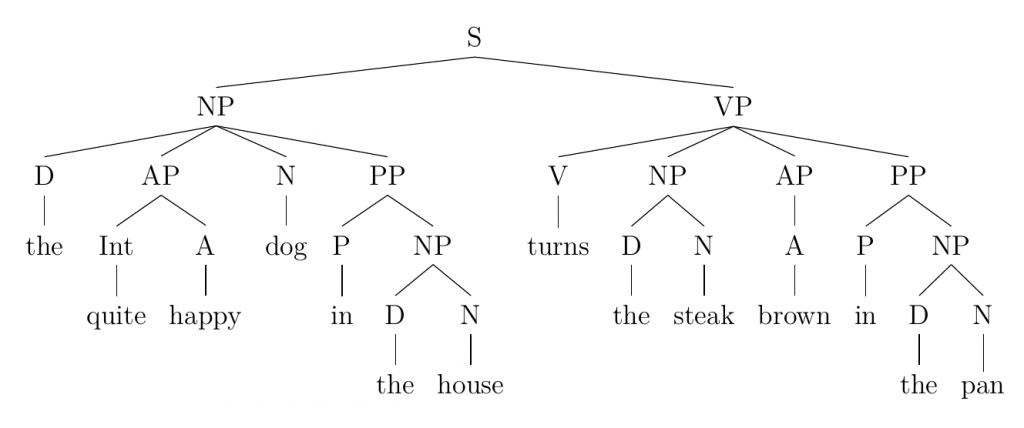
The quite happy dog in the house turns the steak brown in the pan.
The process that we have used to create a working framework for English can be applied to any language, and, in doing this, the cross-linguistic parallels and distinctions become evident.
Thus far, we have worked to create a concise set of PS rules for both English and Indonesian (see also Wolfman, this issue) to highlight their similarities and differences. Following the same processes that we just engaged in for identifying English PSs, Wolfman has created the following PS rules for Indonesian and devised a lexicon for us to work with:
S → NP {VP}
{AP}
{NP}
{PP}
NP → N (A) (D)
VP → V (NP) (PP)
PP → P N
Indonesian Lexicon (adapted from Wolfman (2020), this issue):
| Noun | orang ‘(a) person,’ perempuan ‘(a) woman,’ guru ‘(a) teacher,’ rumah ‘(a) house,’ jalan ‘(a) road,’ restoran ‘(a) restaurant,’ teh ‘(a) tea’ |
| Determiner | itu ‘that, the,’ ini ‘this’ |
| Adjective | kaya ‘rich,’ tua ‘old,’ senang ‘happy,’ besar ‘big,’ baru ‘new’ |
| Verb | duduk ‘sat,’ minum ‘drank,’ lihat ‘saw’ |
| Preposition | di ‘in,’ dekat ‘near’ |
According to these PS rules, Indonesian phrase structure appears very strongly head-initial. This characteristic means that the main lexical item of the phrase (the head) is always found at the beginning of its phrase. English varies considerably more in its headedness compared to Indonesian, and we can see a clear contrast by comparing examples of NPs in the two languages (both of which meaning “the happy teacher”):
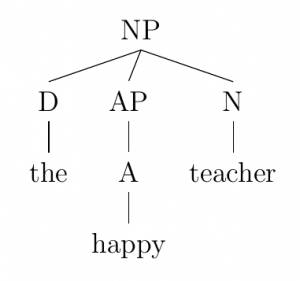
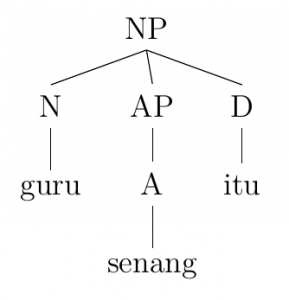
Based on the trees for these two NPs, these sentences are in the exact opposite word orders.[1] This difference points to a more cross-linguistically universal rule of syntax that words with more important lexical content (e.g., adjectives compared to determiners) tend to be placed more closely to the head of the phrase.
As evident in the diagrams above, the Indonesian sentence starkly contrasts the English one. Just like for English, the subject NP in Indonesian is at the beginning of the sentence, but instead of requiring a verbal predicate, Indonesian also has the option for an adjectival, nominal, or prepositional predicate (the option for this slot to be filled by multiple types of lexical items is marked by curly brackets with each option placed vertically adjacent to one another, signifying their mutual exclusivity in the phrase structure). This arrangement arises from Indonesian’s lack of a copular verb, like many other non-Indo-European languages. English, meanwhile, is part of the Indo-European language family. Often called a ‘linking verb’ in primary school grammar classes, the English copular verb is be, and its primary function is to link a subject to a complementary phrase. Compare the following sentences in English and Indonesian with identical meaning:
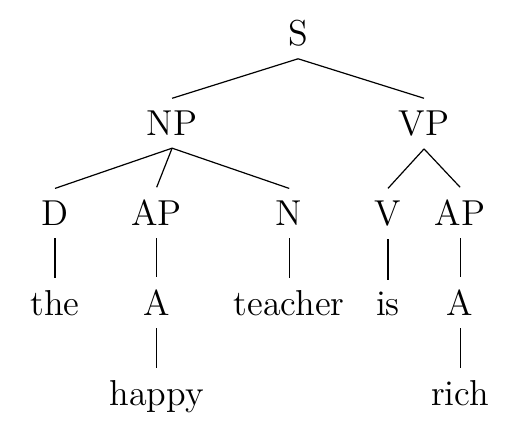
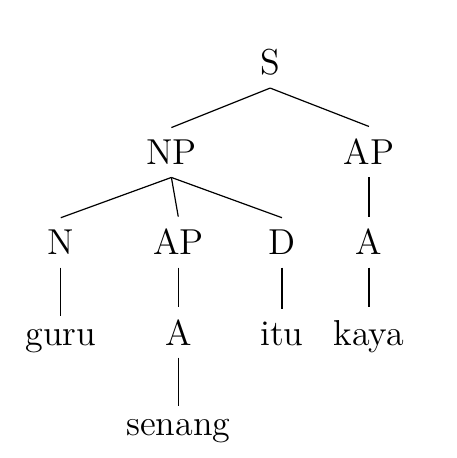
The happy teacher is rich. Guru senang itu kaya.
Teacher happy the rich
‘The happy teacher is rich.’
As the trees demonstrate, it is grammatical in Indonesian for a sentence to lack a verb, despite verbs seeming an obvious necessity from the point of view of an English speaker.
Seeking to understand this difference in perspective is one aspect of the primary goal of syntax (as well as most other fields of linguistics): to identify the processes engaged in and rules followed subconsciously by speakers of a language in order to create meaningful discourse. It is especially important to consider these rules from the point of view of a child learning a language for the first time. Consider an Indonesian child learning to speak, who has no contact with English or any other language with a copular verb and where there is no reason to believe that this child would not eventually learn Indonesian and be able to speak it fluently. For this child, the need for a verbal element like the English be would probably seem absurd, just as any new, English-speaking student of Spanish, Portuguese, or Thai would find it absurd to need two different copular verbs. But, despite all of this, none of these languages are any more efficient in facilitating discourse for its native speakers, nor are they any less linguistically valid and worthy of study.
Armed with enough background information on syntax with specific regards to Indonesian and English PS, we can begin to consider data to update our Indonesian grammar and see what other commonalities might be found between this language and English. To do so, we now have an updated Indonesian lexicon so that we can see how other parts of speech fit into our grammar:
Updated Indonesian Lexicon, Version 1:
| Noun | orang ‘(a) person,’ perempuan ‘(a) woman,’ guru ‘(a) teacher,’ rumah ‘(a) house,’ jalan ‘(a) road,’ restoran ‘(a) restaurant,’ teh ‘(a) tea,’ anak ‘(a) child’ |
| Determiner | itu ‘that, the,’ ini ‘this’ |
| Adjective | kaya ‘rich,’ tua ‘old,’ senang ‘happy,’ besar ‘big,’ baru ‘new,’ jauh ‘far,’ mahal ‘expensive,’ kecil ‘small’ |
| Verb | duduk ‘sat,’ minum ‘drank,’ lihat ‘saw’ |
| Preposition | di ‘in,’ dekat ‘near’ |
| Intensifier | agak ‘rather,’ sedikit ‘a bit,’ terlalu ‘too,’ amat ‘very’ |
This data set gives us our first Indonesian examples ofINTs, which, as in English, are adverbs used to modify adjectives. INTs facilitate an analysis of the Indonesian AP. Consider the following data:
1. * Guru ini agak.
Teacher this rather
‘The teacher is rather.’
2. Guru ini agak senang.
Teacher this rather happy
‘This teacher is rather happy.’
3. * Jalan itu sedikit.
Road that a bit
‘That road is a bit.’
4. Jalan itu sedikit jauh.
Road that a bit far
‘That road is a bit far.’
Looking at these examples, we can see that Indonesian is like English in that INTs cannot stand alone but instead need an adjective to modify. Accordingly, we know that INTs are optional in Indonesian, just as they are in English. Also, we can see that despite being head-initial elsewhere, the Indonesian AP actually looks head-final, since the A follows the INT.
Since we know that the INT is an optional constituent of the Indonesian AP, and we have discerned the position in which it should be placed, our AP rule for Indonesian should be formalized as follows:
AP → (INT) A
Now that we have evidence for APs, it is also necessary to update our sentence rules:
S → NP {VP}
{AP}
{NP}
{PP}
We can illustrate that these rules work with what we know of Indonesian PS by checking them against further data that native speakers have judged as grammatical:
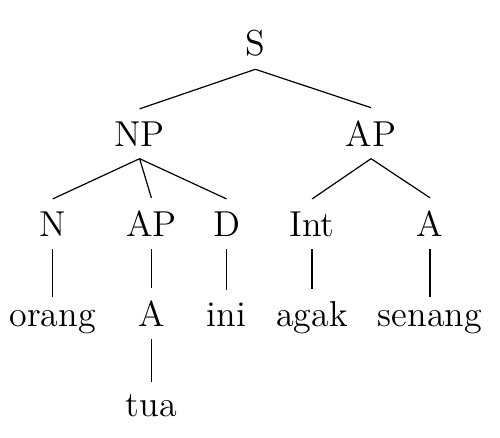
1. Orang tua ini agak senang.
Person old this rather happy
‘This old person is rather happy.’
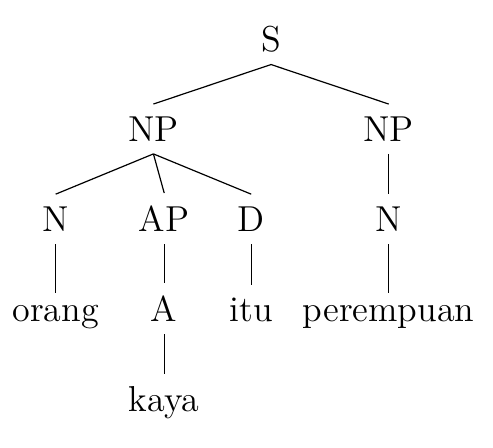
2. Orang kaya itu perempuan.
Person rich the woman
‘The rich person is a woman.’
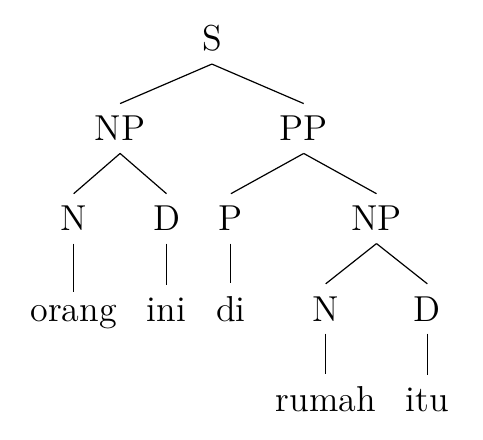
3. Orang ini di rumah itu
Person this in house the
‘This person is in the house.’
Another aspect of Indonesian grammar that we have not yet considered is the function of auxiliary verbs: verbs that function in conjunction with other verbs to affect the tense, aspect, or mood of the action described. English has three important examples of this verb type, the first of which is be (labeled be1 to differentiate from the copula be) when followed by the present participle of the main verb (often called a ‘gerund’ in grammar classes, it uses the -ing suffix), and this formation is used to create the progressive aspect. An example of this is shown below, where be1 is underlined:
- I was running to the store.
- He is following the car.
The progressive, or continuous aspect of a verb, is generally used when the speaker wants to refer to an action that is still in the process of occurring. Verbal aspect, however, is different from verbal tense, as we can see in example (1) (past tense) and example (2) (present tense).
Another important auxiliary in English is have (labeled have1 to differentiate from the possessive have) when followed by the past participle of another verb. English uses this auxiliary to create the perfect aspect, signifying a completed action. Some examples of the perfect aspect in English can be seen below:
- He has beaten him before.
- The man had gone to the store.
Finally, a third type of auxiliary verb is the modal verb (MOD), which signifies a change in mood. Although every VP has a mood (the default is called the indicative), modal verbs can demonstrate anything from desire to obligation to permission, as well as many other sentiments. MODs include words like will, can, should, and may. We know that these verbs all constitute their own category because it is ungrammatical to use more than one in the same sentence (for example: *I will can eat a banana.).
All of these verbal categories may appear together in the same sentence, but only in the order MOD, have1, be1. For instance, example (1) is grammatical whereas example (2) clearly is not:
- The dog must have been cooking steak.
- *The dog is having must cook steak.
An important feature of auxiliary verbs is that they are just that—auxiliary, meaning they never take the role of the principal verb within their VP, since it would be ungrammatical to have a sentence that uses just an auxiliary in the VP. Also, a native speaker of English would intuitively not consider any of these verbs to be the main verb of a sentence in any context where they occur as auxiliary verbs. Thus, our current English VP rule is as follows:
VP → (MOD) (have1) (be1) V (NP) (AP) (PP)*
Before going into an in-depth analysis of Indonesian auxiliary verbs, we should update our lexicon based on the examples provided.
Updated Indonesian Lexicon, Version 2:
| Noun | orang ‘(a) person,’ perempuan ‘(a) woman,’ guru ‘(a) teacher,’ rumah ‘(a) house,’ jalan ‘(a) road,’ restoran ‘(a) restaurant,’ teh ‘(a) tea,’ anak ‘(a) child’ |
| Determiner | itu ‘that, the,’ ini ‘this’ |
| Adjective | kaya ‘rich,’ tua ‘old,’ senang ‘happy,’ besar ‘big,’ baru ‘new,’ jauh ‘far,’ mahal ‘expensive,’ kecil ‘small’ |
| Verb | duduk ‘sat,’ minum ‘drank,’ lihat ‘saw’ |
| Preposition | di ‘in,’ dekat ‘near’ |
| Intensifier | agak ‘rather,’ sedikit ‘a bit,’ terlalu ‘too,’ amat ‘very’ |
| Auxiliary Verb | sudah ‘have1,’ sedang ‘be1,’ harus ‘must’ |
Consider the following data which uses this new verbal category:
1. Perempuan tua ini sudah minum.
Woman old this has drunk
‘This old woman has drunk.
2. Guru itu sedang minum teh.
Teacher the is drinking tea
‘The teacher is drinking tea.’
3. Perempuan itu harus lihat orang ini.
Woman the must see person this
‘The woman must see this person.’
We can see that Indonesian auxiliaries appear before the verb that they modify, just as they do in English. This structure represents another step away from the otherwise strong tendency towards head-initiality that we had earlier seen in Indonesian. However, given our Indonesian data set, we do not see co-occurrence of auxiliaries and thus cannot determine their potential order as we did for English. In turn, our revised VP rule should simply be stated as:
VP → (AUX) V (NP) (PP)
Using the examples provided, this rule can be illustrated as follows:
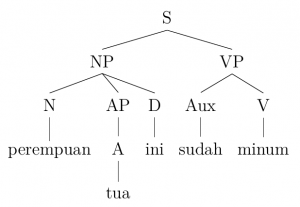
1. Perempuan tua ini sudah minum.
Woman old this has drunk
‘This old woman has drunk.’
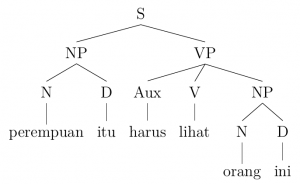
2. Perempuan itu harus lihat orang ini
Woman the must see person this
‘The woman must see this person.’
Another important feature of any language is the way that it deals with sentential negation. In English, this is done using two transformation rules:
Do1-insertion: Take a sentence with no auxiliary verbs present and insert do1.
NEG-insertion: Take a sentence and insert not after the left-most auxiliary verb.
It is important to note that Do1-insertion is not necessary for negation if the sentence already has an auxiliary present.
Before looking at how Indonesian deals with negation somewhat differently, we should update our lexicon again.
Updated Indonesian Lexicon, Version 3:
| Noun | orang ‘(a) person,’ perempuan ‘(a) woman,’ guru ‘(a) teacher,’ rumah ‘(a) house,’ jalan ‘(a) road,’ restoran ‘(a) restaurant,’ teh ‘(a) tea,’ anak ‘(a) child’ |
| Determiner | itu ‘that, the,’ ini ‘this’ |
| Adjective | kaya ‘rich,’ tua ‘old,’ senang ‘happy,’ besar ‘big,’ baru ‘new,’ jauh ‘far,’ mahal ‘expensive,’ kecil ‘small’ |
| Verb | duduk ‘sat,’ minum ‘drank,’ lihat ‘saw,’ pergi ‘go’ |
| Preposition | di ‘in,’ dekat ‘near’ |
| Intensifier | agak ‘rather,’ sedikit ‘a bit,’ terlalu ‘too,’ amat ‘very’ |
| Auxiliary Verb | sudah ‘have1,’ sedang ‘be1,’ harus ‘must’ |
| NEG marker | tidak |
While Indonesian negation functions very similarly to the English method, instead of placing the NEG within the predicate, Indonesian places it at the sentence-level between subject and predicate. Take these sentences for example:
1. Guru itu minum teh.
Teacher the drank tea
‘The teacher drank tea.’
2. Guru itu tidak minum teh.
Teacher the NEG drink tea
‘The teacher didn’t drink tea.’
3. Guru itu tidak sudah minum teh.
Teacher the NEG has drunk tea
‘The teacher has drunk tea.’
4. Guru itu tidak kaya.
Teacher the NEG rich
‘The teacher is not rich.’
As we can see, tidak always immediately precedes the first word of the predicate when the sentence is negative. In this way, Indonesian differs from English, since NEG does not follow any accompanying auxiliary verb. Likewise, as we can see in example (2), if the original sentence does not already have an auxiliary verb present, there is no need to insert one as would typically be done in English. Instead, Indonesian simply places tidak in front of the entire predicate phrase. In this way, Indonesian negation is more similar to that of the Romance Languages where, for example in Portuguese, it is grammatical to say the following:
(A) Eu como peixe
I eat fish
‘I eat fish’
(B) Eu não como peixe
I NEG eat fish
‘I don’t eat fish’
Since the placement of the negation marker is more predictable than it is in English, we do not have to make a transformation rule to go with it. Instead, we can formalize it in our PS rules for Indonesian sentences:
S → NP (NEG) {VP}
{AP}
{NP}
{PP}
We can prove that this rule works as part of a generative grammar by modelling it on the following trees of grammatical sentences from our Indonesian data set:
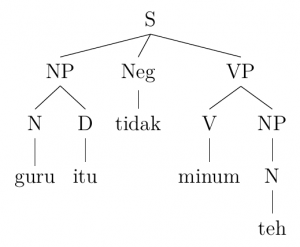
1. Guru itu tidak minum teh.
Teacher the NEG drink tea
‘The teacher didn’t drink tea.’
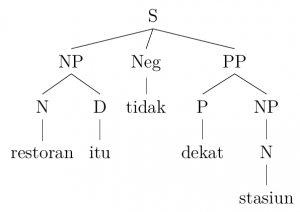
2. Restoran itu tidak dekat stasiun.
Restaurant the NEG near station
‘The restaurant isn’t near a station.’
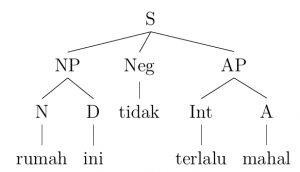
3. Rumah ini tidak terlalu mahal
House this NEG too expensive
‘This house isn’t too expensive.’
Based on what we have seen regarding Indonesian auxiliary verbs and negation, it is clear that the language differs in many key ways from the analogous structures found in English. For instance, there are no changes in the inflectional forms of verbs in order to create participles when following an auxiliary verb (such as -en and -ing), which is completely obligatory in English. Similarly, the negation marker of Indonesian does not require the presence of an auxiliary verb, as it does in English. In this way, we see two important distinctions that reflect the larger, disparate relationship of two unrelated languages.
Despite this, neither language can prove itself to have a more sophisticated manner of communication, as both work to adequately and logically convey the same information within the minds of its native speakers. We can see that neither language is wholly head-final or initial.[2] Further, we can see that the distance from the head of particular types of constituents within a phrase is always consistent, as exemplified below:
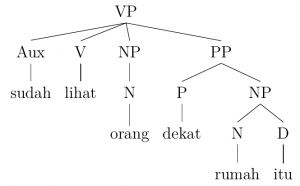
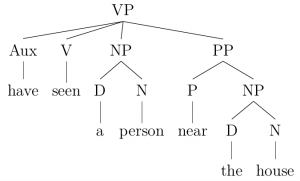
1. sudah lihat orang dekat rumah itu. have seen a person near the house.
have seen person near the house
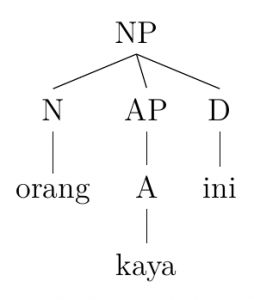
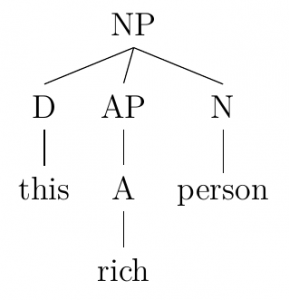
2. orang kaya ini. this rich person.
this rich person
In all of these phrase types, regardless of their headedness, constituents with more important lexical content (such as direct object NPs or adjectives) tend to be found closer to the head, while ones that are less lexically important tend to be found farther away from the head (such as optional modifiers, PPs, and determiners).
Although there are many aspects of Indonesian and English that differentiate the two languages, the majority of these differences are only surface-level. Upon further examination, certain syntactic parallels run deeper than either language’s distinct and unrelated genealogy. Investigating these parallels further in the context of other unrelated languages would provide insight into whether they represent cross-linguistically relevant trends or coincidental similarities between English and Indonesian. Such a future course of study could identify potential linguistic universals and further explicate the processes undergone in the minds of native speakers for a language to take shape.
Works Cited
Wolfman, Michael. “Parallelism in Language: A Cross-Linguistic Analysis of English and Indonesian.” The Classic Journal, 2020, theclassicjournal.uga.edu/index.php/2020/04/22/parallelism-in-language-a-cross-linguistic-analysis-of-english-and-indonesian/.
Notes
[1] If we were to add a PP-complement to the English N-head, this complement would follow the head, as in the happy teacher of linguistics. So, while English is not as consistently head-initial as Indonesian, it is clearly not head-final either.
[2] The data considered in Wolfman (2020, this issue) makes Indonesian look strictly head-initial, but, given that Int and Aux precede the heads they modify, respectively, we know that head-initiality is just a tendency in Indonesian.
Acknowledgements: I would like to thank Dr. Lee-Schoenfeld for being an incredible syntax professor and encouraging me to pursue the field more seriously.